







As technology advances, we have new and improved ways of dealing with various problems. One example would be the use of high-resolution cameras in traffic. They can be placed on congestion points for the purpose of traffic reports (so commuters would know which places to avoid on their way to work).
Also, we can monitor car flows for making a decision about the development of future roads, and use them for quick reactions in case of accidents or similar problems. These tasks are a lot easier if cameras have high resolution. But with that improvement, often we have a picture so clean that we can read license plates of the cars passing by.
Our task was to perform the detection and concealment of such readable license plates.
Why conceal license plates?
Besides running from police, one couldn’t think of a good reason for concealing license plate number. Well, that was maybe the case, but lately, there has been a lot of concern regarding the private data of individuals.
The main drive of this is the introduction of GDPR, a set of European Union regulations that govern how companies have to manage personal data. GDPR covers any data that can be used to identify a person, even indirectly. License plate numbers are personal information under GDPR because you can theoretically identify the owner of the car if you know their license plate number.
This could be exploited to track someone’s whereabouts, so we need an efficient way to conceal readable license plates. To conceal them, we must first be able to detect them. This is a complex task due to the continuous flow of cars passing by the cameras.
Because of its complexity and tediousness, this task is not suitable for humans, but it is perfect for a machine system. A system for this task needs to be fast, precise, and generalized to do the same thing on all cameras.
How do we build such a system? Well, the answer is a technology called Deep Learning. Because of simplified ways to collect huge amounts of data, machines that can perform fast computations, and advances in the field of AI, Deep Learning today is the defacto state-of-the-art approach for Computer Vision.
Overview of the system
The system is made up of three major parts:
- Object detection
- Landmark detection
- REST API

system overview
Object detection
First, we want to detect all license plates in one frame (one frame could contain multiple cars). The output here is a bounding box of detected license plates for concealment. We have around 13.000 labeled images for this task.
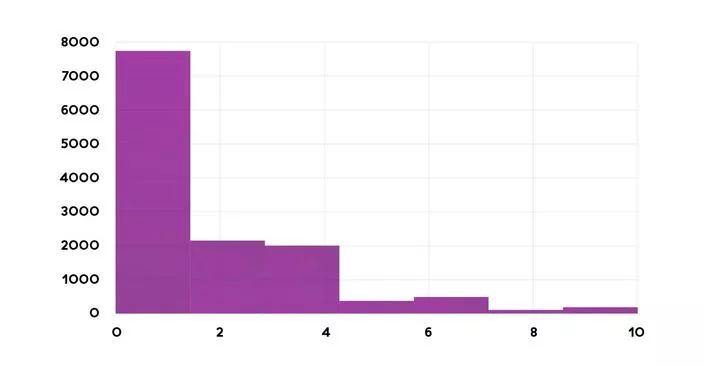
Distribution of license plates on frames
We could build the model from scratch, but there are other already trained models on similar tasks which we could use. For this, we use the Tensorflow Object Detection API, because it makes it easy to construct, train and deploy object detection models. This API also has a number of different trained models; therefore we can choose the best suitable model for our needs. These models are not trained for detecting license plates, but we can use them and fine-tune them on our dataset for our specific task Transfer learning.
We mentioned that our system must be both fast and precise, so we have a trade-off between speed and accuracy. The most precise model for object detection is Faster R-CNN model, but the fastest one is SSD MobileNet (source). After experiments with both, we chose SSD MobileNet.
Although Faster R-CNN has magnificent accuracy, this model is very slow. Cameras send frames every few seconds, and we must process the images and detect all license plates in a short period of time so our system would be efficient. With advanced hardware, this is achievable but also very expensive. Also, it is not scalable – If we add more cameras, the cost will increase rapidly.
SSD MobileNet is a lot faster than Faster R-CNN but it has lower accuracy. Is there a way we could improve accuracy of our system with SSD MobileNet as an object detection model, but without losing too much speed? Well, this is the task of the next part of our system.
Landmark detection
The task of this model is to give us finer and better detections of license plates. The idea is simple: For each detection in a frame we send a bounding box of detected license plates to a landmark detection model to find corners of a specific license plate.
We built this model from scratch in KERAS with Tensorflow as backend. By using a Convolutional Neural Network (CNN) that takes an image with 100×100 size of car with license plate as input, and outputs x,y coordinates for all 4 corners of license plate.
The model was trained on 20.000 images of license plates and annotations of the license plate corners. By detecting corners, we have a much better approximation of license plate location, and thus, improved precision.
The model is not complex (for CNN) – we set up simple neural network architecture with two convolutional layers followed by two fully connected dense layers and an output layer (the model has 3 million trainable parameters), therefore its predictions are very fast (3 ms per license plate on 2,4 GHz Intel Core i7) and have a tiny effect on the speed of detections, so this gives us precisely what we want.
But with this model, we gain another huge advantage. Object detection models always output rectangular shapes of their detections. Because of the angle of the camera watching the traffic, license plates on the frames don’t have a proper rectangular form. With corner detection, we can get much finer detection and practically get some quadrangular shapes of the detected license plates.

Comparison of the object (in yellow) and landmark (in red) detection
It is important to notice that we expand the bounding box of detected license plates because we want a bigger context and more information for our landmark detection model to achieve better generalization.
Another reason is mentioned lower accuracy of SSD MobileNet – this model sometime returns a bounding box that doesn’t cover the whole license plate.
REST API
The purpose of the REST API is coordination between cameras and deep learning models for detection. The app takes requests (video streams frame by frame) from clients (traffic cameras) and delegates them to the previously mentioned modules. After detection and blurring part frame is sent back to the client. We got an additional significant boost in the computational speed, by building a Tensorflow package from the source code.
Summary & results
To summarize the system, this is what it all looks like:
1
A camera records the road and every few seconds sends a frame to a web interface of our system.
2
Each frame is preprocessed and then sent to an object detection model for recognizing all license plates in the frame.
3
An expanded bounding box of each detected license plate is sent to the landmark detection model, which returns predictions of each of the four corners of a given license plate.
4
For each detected license plate in the frame, we blur the part that is between corners.
5
Frame with blurred license plates gets returned to the client.
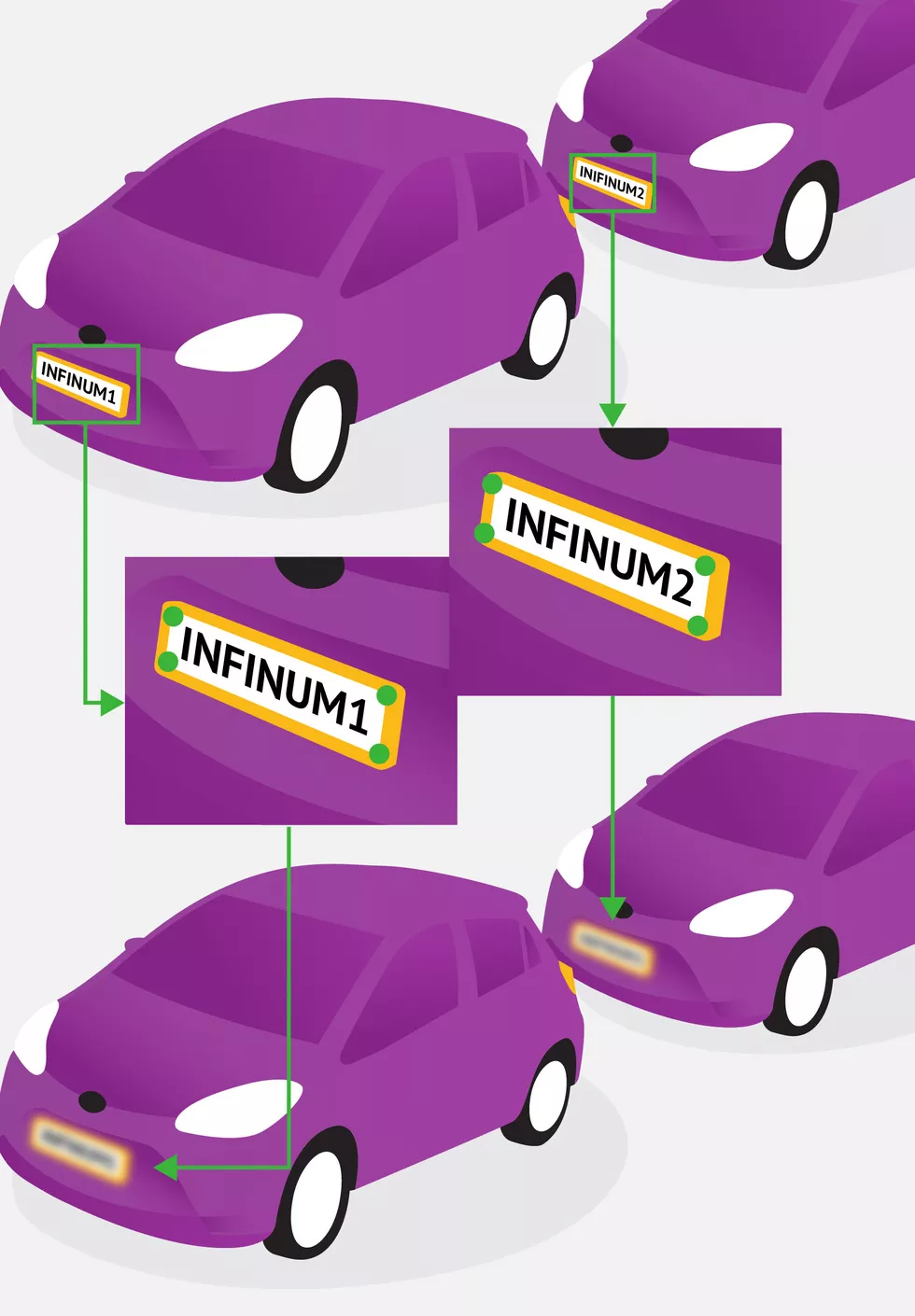
License plate detection pipeline
In this blog post we have shown that it is possible to build a license plate concealment system that is both fast and precise. Furthermore, the system is generalized to work equally well on all cameras. All this is possible with emerging deep learning techniques.
Need help with your Machine Learning projects? Get in touch, we’d love to help with your challenge.



